Client
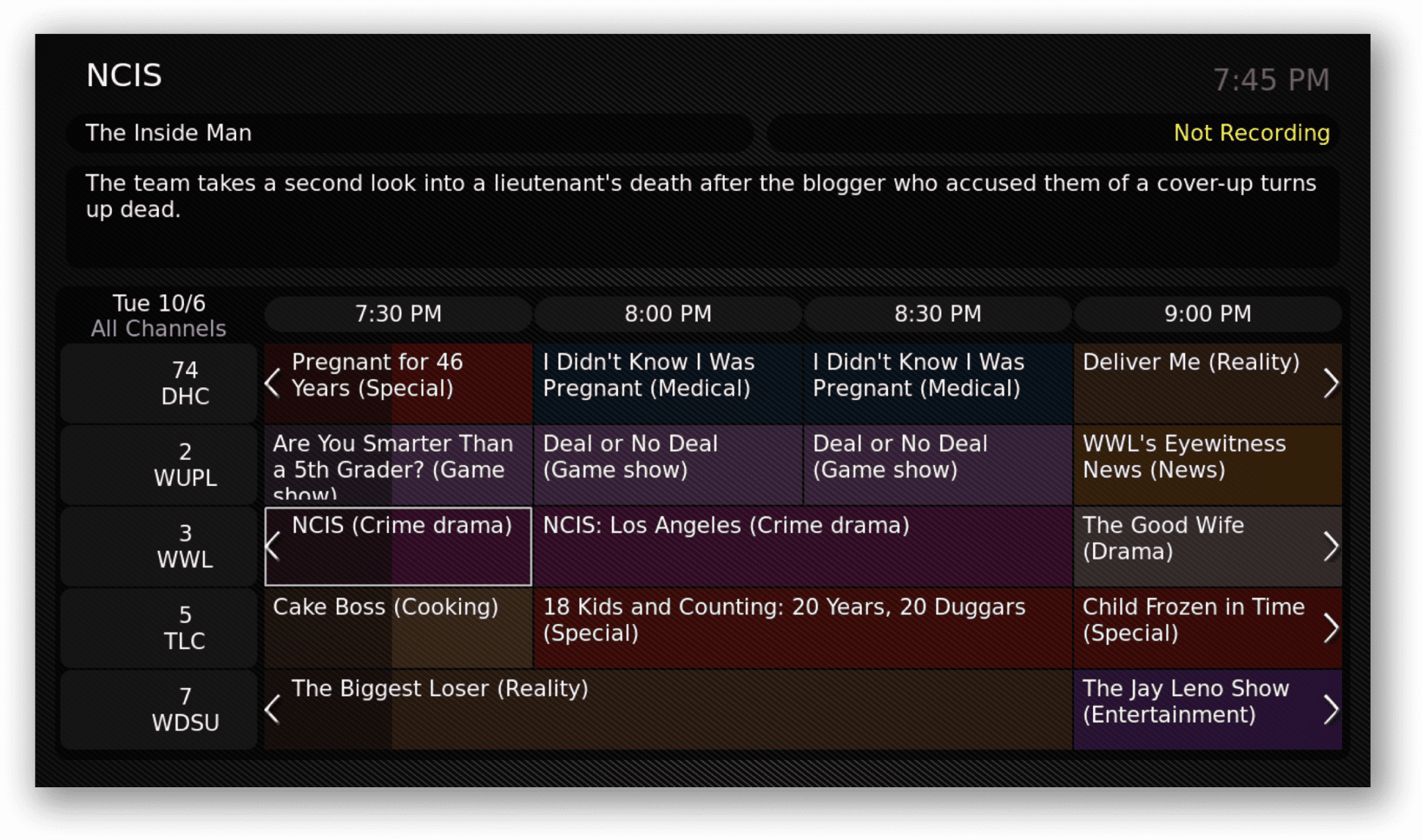
The varied requirements of different media channels and broadcasters make it challenging to prepare program descriptions.
There are ways to automate the task, but even these require lots of manual effort owing to the preparation of templates and missing metadata.